Using «IF» in expressions vs using «Set Analysis»
11/19/2013 Deja un comentario
In this article I will try to clarify all the differences and similarities that occur when in an expression we can use either statements like IF or its «equivalent» SET ANALYSIS, and downplayed this supposed equivalence because in some cases you get (almost) the same result and not in others for which it is necessary to understand the operation of each mechanism to know which should be applied in each scenario.
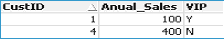
Customers:
load * inline [
CustID, Anual_Sales, VIP
1 , 100, Y
2 , 200, Y
3 , 300, Y
4 , 400, N
];
Claims:
Load * inline [
CustID, ClaimID, Claimed_Amount
1, 1, 5
1, 2, 8
4, 3, 15
4, 4, 1
];
So we get:
Customers:

Claims:
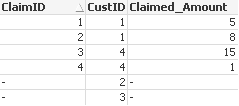

Now see different indicators and the correct ways to get them and other erroneous ways we should avoid:
1 – Amount claimed for VIP clients:
a-Using Set Analysis (CORRECT):
![]()

And because the model’s relationships:
Claims Table——-> 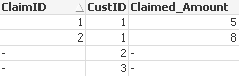
Finally QV sum Claimed_Amount getting 13.
b- Using «IF» (CORRECT):
![]()
Here QV joins both tables (doing a Natural Join) which yields something like:

It can be seen that the result 13 obtained is correct and only shows rows where the expression is different from zero, which could change by check «Supress zero values» in the tab «Presentation», obtaining:

This is because what we are adding is in the «far right» of the join, ie in the Claims table (the right side of our joined table) remain the same number of rows than before the join.
In this first case (1) using IF or Set Analysis is, at least in principle and only effect of the outcome, identical, but later we will see some subtle differences.
2 – Annual Turnover committed of the customers: it seeks to show «how much could be lost if not solve the claims»
a-Using Set Analysis (CORRECT):
The data model is filtered and searched for rows that have any value (‘*’) in ClaimID.
 By doing this QV filters the model through the relationship obtaining a Customers resultset as follows:
By doing this QV filters the model through the relationship obtaining a Customers resultset as follows:
 And showing the result properly:
And showing the result properly:
b-Using «IF» (WRONG):
Here QV first makes a Natural Join between Customers and Claims, and this happens because the expression is using fields of the two tables (this «force» the join between tables):

Then over the «result set» obtained QV runs the expression row by row looking for those that meet the criteria (that have at least one claim) and grouping according to the corresponding dimension, yielding the following WRONG result:
![]()
Count(DISTINCT if(not isnull(ClaimID),Cust_ID))

Here we combine the two tables fields (which led us to an error in 2b) but internally there is a step that allows a correct result unlike the alternative explained in 2b.
In the first place for each different CustID QV counts the number of values that are in ClaimID, obtaining a temporary and intermediate table like this:

Then QV only gets 1 and just 1 line for each customer who has at least one claim. It’s really this table which QV use to join with Customers (Anual_Sales field) in the expression:
sum(if(aggr(count(ClaimID),CustID)>=1 , Anual_Sales))
So that does not «multiply» the rows of the parent table (Customers) when join it with detail (Claims). Customers joins with the temporary table made by AGGR function and it has a 1 to 1 ratio, so finally unique amounts are added, getting the right result.
d- From script using group by and Flags (CORRECT):
As we saw the problem to avoid is that «multiplied» the rows in the table where is the field you want to sum when doing joins with other tables in the model. In a very similar way to AGGR we can «mark» customers rows who have claims at runtime script and then just add the annual billings of these customers without joins with any other table. This is done by creating a new field in the parent table (Customers) that functions as a flag. So in our script add:
left join(Customers)
LOAD CustID,
if(isnull(count(ClaimID)),’N’,’Y’) as Commited
RESIDENT Claims
GROUP BY CustID;

When there is the possibility of using either IF or Set Analysis QV advisable to use Set Analysis because performance reasons, but is usually even more performant resolution via script, especially if there is important data volume and / or a complex model. By other side use Aggr in this type of model can be very expensive in memory and cpu, especially if you have no control over other filters that the user might be doing.
A final consideration about using Set Analysis: in some circumstances and closely linked to the board design and the use cases presented by the user, it can result a bit confusing. For example suppose we have a board with a dynamic table and a selector like this:

![]()
If the user had selected VIP = «N» the Pivot Table will ignore that selection as the Set Analysis (such as it is written) ignores the user selection, producing it a result that could be confusing to an unsuspecting user. This does not happen when using IF, but besides having a poor performance is not always achieved the right and desired result.
 QlikView Notes
QlikView Notes
{kind=link}